【AI短讯】Midjourney V7再升级
2025年5月3日,Midjourney V7 推出实验性模式。这是V7模型的加速版本,发布默认快速模式,成本降为之前一半,与V6作业价格大致相同。快速模式下作业约40秒,turbo模式18秒。质量方面,新手部有轻微改进,想要旧版本可用–q 2获取,还新增“实验性”–q 4模式,或有更好连贯性和细节。需注意,–oref作业成本仍是正常fast模式2倍,草稿模式无变化。
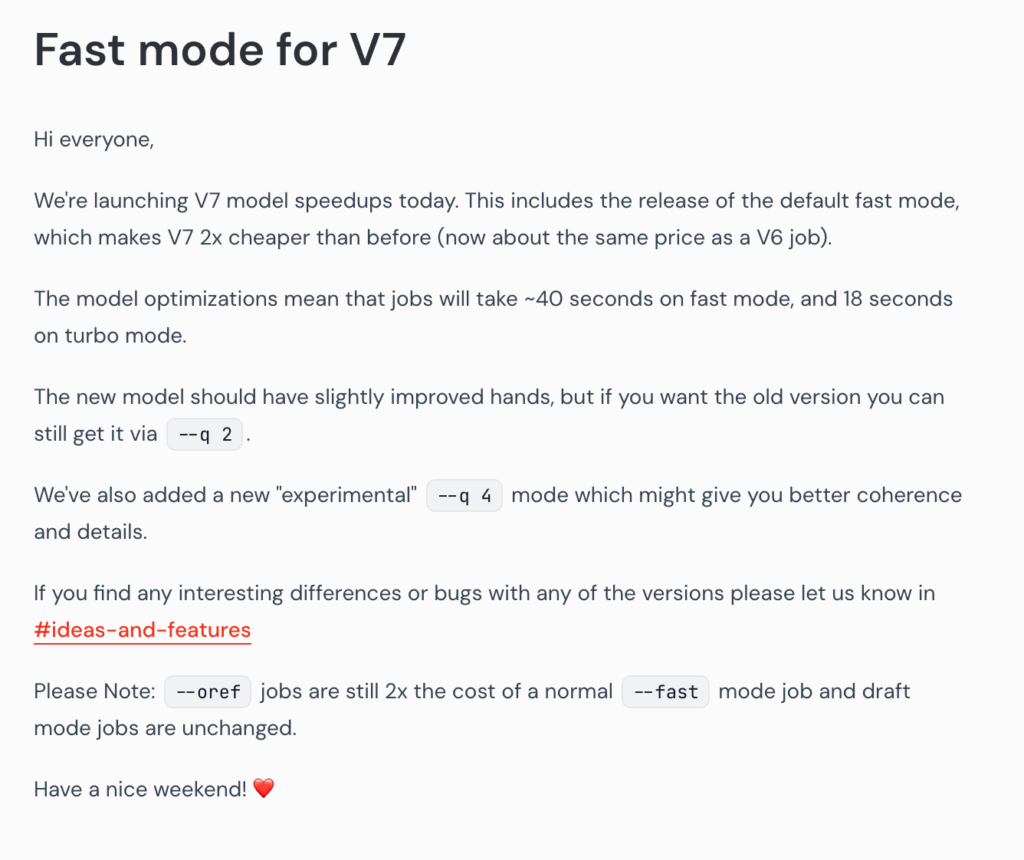
2025年5月3日,Midjourney V7 推出实验性模式。这是V7模型的加速版本,发布默认快速模式,成本降为之前一半,与V6作业价格大致相同。快速模式下作业约40秒,turbo模式18秒。质量方面,新手部有轻微改进,想要旧版本可用–q 2获取,还新增“实验性”–q 4模式,或有更好连贯性和细节。需注意,–oref作业成本仍是正常fast模式2倍,草稿模式无变化。
模型简介Xiaomi MiMo 是小米推出的首个开源推理大语言模型,参数规模为 7B(70 亿),聚焦数学推理与代码生成任务。通过高推理密度的预训练数据(总计 25 万亿 tokens)及强化学习算法优化,该模型在 7B 参数规模下实现了推理能力的突破性提升,技术报告显示其性能超越了 OpenAI o1-mini 和阿里等竞品模型 。小米团队通过联动预训练与后训练阶段的数据和算法创新(如挖掘富推理语料、合成 200B tokens 推...
Cobra 可为线稿漫画自动上色,并支持多角色参考,助力漫画创作更高效。 项目地址:官网 | GitHub 我们可以用这种工具,进行一些漫画的创作,特别适合哪些想要创作漫画的小伙伴。

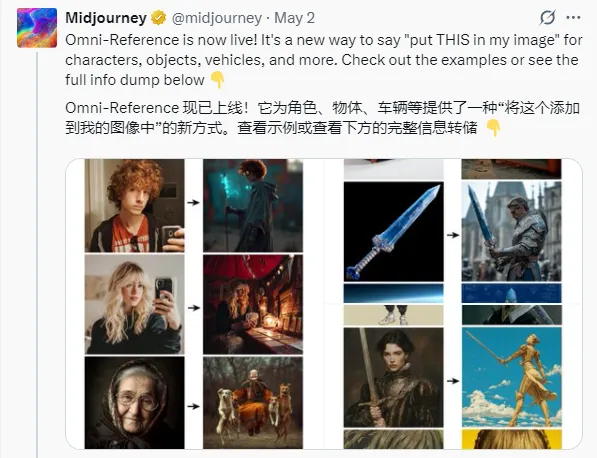
一、引言 在AI图像生成领域,Midjourney一直是备受瞩目的佼佼者。近期,Midjourney推出了一项名为“Omni – Reference”(全向参考)的革命性新功能,为创作者们带来了前所未有的创作自由和精准控制,让AI绘画真正实现了“想啥画啥”的创意愿景。本文将详细介绍Midjourney Omni的功能特点、使用教程以及应用场景等内容,帮助大家快速掌握这一强大的新工具。 二、Omni – Reference功能介...
技术突破:混合推理架构的革新 在AI演进的浪潮中,阿里通义实验室推出的Qwen3系列以”混合推理架构”开辟了新路径。这一创新通过动态调配计算资源,实现了基础模型与扩展功能的分离式处理。具体表现为: 双模运行:基础模型处理通用任务,扩展能力模块通过API调用实现功能升级 资源弹性:根据实际需求动态分配GPU集群,使高参数模型的部署成本降至传统方案的35% 架构创新...

一、Nunchaku介绍 Nunchaku是由MIT Han Lab开发的4位扩散模型高效推理引擎,专为优化生成式模型(如Stable Diffusion)的推理速度和显存占用设计。结合SVDQuant量化技术,它在保持生成质量的同时显著提升性能。其技术优势如下: 显存优化:相比传统BF16模型,显存占用减少3.6倍(例如16GB显存设备可运行更大模型)。 速度提升:在16GB显存设备上,推理速度比16位模型快8.7倍,比传统4位量化(NF...
1.列出所有已安装模型 ollama list 2.安装/运行模型 ollama run XXXX 例如安装 deepseek:ollama run deepseek-r1:8b 3.删除模型 ollama rm XXXX 例如删除 deepseek:ollama rm deepseek-r1:8b 4.查看模型信息 Ollama show XXXX 5.启动 Ollama Ollama serve
模型介绍 作为Flux模型家族中的创新之作,Shutter Jaguar以其独特的四步生成流程,将文本转化为引人注目的电影级图像。这种革命性的AI技术不仅能够生成高度逼真的视觉内容,更通过Apache 2.0开源许可,为创意和应用提供了前所未有的自由度与可能性。 Shutter Jaguar 提供了 FP16 版本的同时,还提供了 FP8和 GGUF 量化版本,配置较低的电脑可以根据自身电脑配置选择对应版本 模型官方 F16下...

写在前面 在人工智能领域,大型语言模型(LLM)的应用日益广泛,但许多用户希望能够在本地环境中进行部署和运行,以满足特定的数据隐私、定制化需求或离线使用场景。 DeepSeek-R1 是最近非常火爆的一个高性能的 AI 推理模型,专注于数学、代码和自然语言推理任务。 Ollama 作为一种强大的工具,能够轻松帮助用户在本地环境实现大型语言模型(如 DeepSeek-R1)的部署与管理。本文将详细介绍如...


ComfyUI-TeaCache 插件介绍 ComfyUI-TeaCache 是一款专为 ComfyUI 打造的高效缓存插件,通过对计算结果的智能缓存机制,显著提升了 ComfyUI 的运行效率,尤其在多次重复运行类似任务的场景下能够有效节省时间和计算资源。 功能与效果 智能缓存 TeaCache 会根据输入参数和任务的特性,自动判断是否可以复用之前的计算结果。如果某次任务的输入参数与缓存中的记录一致,插件会直接返回缓存结果,而无需重复...
